
Introduction
Lawyers know a lot about a wide range of subjects—the result of constantly dealing with a broad variety of factual situations. Nevertheless, most lawyers might not know much about machine learning and how it impacts lawyers in particular. In this article, I provide a short and simple guide to machine learning at a level understandable to the typical attorney.
The phrase “artificial intelligence” usually refers to machine learning in one form or another. It might appear as the stuff of science fiction, or perhaps academia, but in reality machine learning techniques are in broad use today. Such techniques recommend books for you on Amazon, help sort your mail, find information for you on Google, and allow Siri to answer your questions.
In the legal field, Westlaw and Lexis use machine learning tools in their natural-language search and other features. ROSS Intelligence is an “AI” research tool that finds relevant “phrases” from within cases and other sources in response to a plain-language search. Kira Systems uses machine learning to quickly analyze large numbers of contracts. These are just two of dozens of new, machine-learning-based products. On the surface, these tools might seem similar to current legal products, but you will see by the end of this article that they do something fundamentally different, making them not only potentially far more efficient and powerful, but disruptive as well. For example, machine learning is the “secret sauce” that enables ride-sharing services like Uber, allowing it to efficiently adjust pricing to maximize both the demand for rides and the availability of drivers, predict how long it will take a driver to pick you up, and calculate how long your ride will take. With machine learning, Uber and similar companies are rapidly displacing the traditional taxicab service. Understanding what machine learning is and what it can do is key to understanding its future effects on the legal industry.
What Is Machine Learning?
Humans are good at deductive reasoning. For example, if I told you that a bankruptcy claim for rent was limited to one year’s rent, you would easily figure out the amount of the allowed claim. If the total rent claim were $100,000, but one year’s rent was $70,000, you would apply the rule and deduce that the allowable claim is $70,000. Now reverse the process. Assume I told you that your client was owed $100,000 and that the annual rent was $70,000, and then told you that the allowable claim was $70,000. Could you figure out how I got that answer? You might guess that the rule is that the claim is limited to one year’s rent, but could you be sure? Perhaps the rule was something entirely different. This is inductive reasoning, and it is much more difficult to do.
Machine learning techniques are computational methods for figuring out “the rules,” or at least approximations of the rules, given the factual inputs and the results. Those rules can then be applied to new sets of factual inputs to deduce results in new cases.
Here is an example that is easy to understand. You all know the old number series games. For example:
2 4 6 8 10 _?_
The next number is 12, right? Here, the inputs are the series of numbers 2 through 10, and from this we induce the rule for getting the next number—add 2 to the last number in the series. Here is another one:
1 1 2 3 5 _?_
The next number is 8. This is a Fibonacci sequence, and the rule is that you add together the last two numbers in the series.
These games illustrate the use of inductive reasoning to figure out the rule. You then apply that rule to get the next number. Broken down a little, the prior game looks like this:
Input Result
1 1 2
1 1 2 3
1 1 2 3 5
1 1 2 3 5 _?_
We look at the group of inputs and induce a rule that gives us the shown results. Once we have derived a workable rule, we can apply it to the last row to get the result “8,” but more importantly we can apply it to any group of numbers in the Fibonacci sequence. This is a simple (very simple) example of what machine learning does.
Naturally, real-world problems are more complex. Instead of a short series of numbers as inputs, a real-world problem might use dozens, perhaps thousands, of possible inputs that might be applied to an undiscovered rule to obtain a known answer. We also do not necessarily know which of the inputs are the ones our unknown rule uses!
To solve a more complex problem, we might begin by building a database with the relevant points of information about a large number of cases, in each instance collecting the data points that we think might affect the answer. To build our prediction model, we would select cases at random to use as a “training set,” putting the remainder aside to use as a “test set.” Then we would begin to analyze the various relationships among the data points in our training set using statistical methods. Statistical analytics can help us identify the factors that seem to correlate with the known results and the factors that clearly do not matter.
Advanced statistical methods might help us sort through the various relationships and find an equation that takes some of the inputs and provides an estimated result that is pretty close to the actual results. Assuming we find such an equation, we then try it out on the test set to see if it does a good job there as well—predicting results that are close to the real results. If our predictive model works on our test set, then we consider ourselves lucky.
For real-world problems, this kind of analysis is difficult. The job of collecting the data, cleaning it, and analyzing it for relationships takes a lot of time. Given the large number of potential variables that affect real-world relationships, identifying those that matter is somewhat a process of trial and error. We might get lucky and generate results quickly, we might invest substantial resources without finding an answer at all, or the relationships might simply prove to be too complex for the methods I described to work adequately. Inductive reasoning is difficult to do manually. This brings us to machine learning. Machine learning can efficiently find relationships using inductive reasoning.
As an example of what machine learning can do, consider these images:

Assume we want to set up a computer system to identify these handwritten images and tell us what letter each image represents. Defining a rule set is too difficult for us to do by hand and come up with anything that is remotely usable, but we know there is a rule set. The letter A is clearly different from the letter P, and C is different from G, but how do you describe those differences in a way a computer can use to consistently determine which image represents which letter?
The answer is that you don’t. Instead, you reduce each image to a set of data points, tell the computer what the image is of, and let the computer induce the rule set that reliably matches all the sets of data points to the correct answers. For the image recognition problem, you might begin by defining each letter as a 20 pixel by 20 pixel image, with each pixel having a different grey-scale score. That gives you 400 data points, each with a different value depending on how dark that pixel is. Each of these sets of 400 data points is associated with the answer—the letter they represent. These sets become the “training set,” and another database of data points and answers is the “test set.” We then feed that training set into our machine-learning algorithm—called a “learner”—and let it go to work.
What does the “learner” actually do? This is a little more difficult to explain, partially because there are a lot of different types of learners using a variety of methods. Computer scientists have developed a number of different kinds of techniques that allow a computer program to infer rule sets from defined sets of inputs and known answers. Some are conceptually easier to understand than others. In this article, I describe how one type works. Machine learning programs will use a variation of one or more of these techniques. The most advanced systems include several techniques, using the one that fits the specific problem best or seems to generate the most accurate answers.
In general, think of a learner as including four components. First, you have the input information from the training set. This might be data from a structured, or highly defined, database, or unstructured data like you might find in a set of discovery documents. Second, you have the answers. With a structured database, a particular answer will be closely identified with the input information. With unstructured information, the answer might be a category, such as which letter an image represents or whether a particular e-mail is spam, or the answer might be part of a relationship, such as text in a court decision that relates to a legal question asked by a researcher. Third, you have the learning algorithm itself—the software code that explores the relationships between the input information and the answers. Finally, you have weighting mechanisms—basically parts of the algorithm that help define the relationships between the input information and the answers, within the confines of the algorithm. Once you have these four components, the learner simply adjusts the weighting mechanisms in a controlled manner until it finds values for the weighting mechanisms that allow the algorithm to accurately match the input information with the known correct answers.
The techniques take a lot of computational power. Machine learning programs, however, can figure out the relationships when there are millions of data points and billions of relationships—when modeling the systems is impossible to do by hand because of the complexity. Machine learning systems are limited only by the quality of the data and the power of the computers running them.
An Example of a Machine Learning System
One example of a type of machine learning system is a neural network. The term “neural network” conveys the impression of something obscure and mysterious, but it is probably the easiest form of a machine learning system to explain to the uninitiated. This is because it is made up of layers of a relatively simple construct called a “perceptron.”
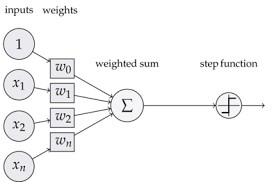
Credit: https://blog.dbrgn.ch/2013/3/26/perceptrons-in-python/
This perceptron contains four components, the first being one or more inputs represented by the circles on the left. The input is simply a number, perhaps between 0 and 1. It might represent part of our input information, or it might be the output from another perceptron.
Second, each input number is given a weight—a percentage by which the input is multiplied. For example, if the perceptron has four inputs of equal importance, each input is multiplied by 25 percent. Alternatively, one input might be multiplied by 70 percent while the other three are each multiplied by 10 percent, reflecting that one input is far more important than the others.
Third, these weighted input numbers are added to generate a weighted sum—a single number that reflects the weights given the various inputs.
Fourth, the weighted sum is fed into a step function. This is a function that outputs a single number based on the weighted sum. A simple step function might output a “0” if the weighted sum is between 0 and .5, and a “1” if the weighted sum is between .5 and 1. Usually a perceptron will use a logarithmic step function designed to generate a number between, say, 0 and 1 along a logarithmic scale so that most weighted values will generate a result at or near 0, or at or near 1, but some will generate a result in the middle.
Some systems will include a fifth element: a “bias.” The bias is a variable that is added or subtracted from the weighted sum to bias the perceptron toward outputting a higher or lower result.
In summary, the perceptron is a simple mathematical construct that takes in a bunch of numbers and outputs a single number. That output number might be fed to another perceptron, or it might relate to a particular “answer.” For example, if your learner is doing handwriting recognition, you might have a perceptron that tells you the image is the letter “A” based on whether the output number is closer to a 1 than a 0.
In a neural network, the perceptrons typically are stacked in layers. The first layers receive the input information for the learner, and the last layer outputs the results.
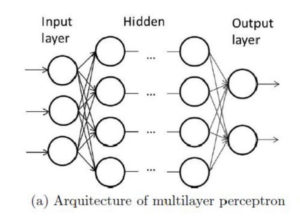
Credit: http://www.intechopen.com/books/cerebral-palsy-challenges-for-the-future/brain-computer-interfaces-for-cerebral-palsy
In between are what are called “hidden layers” of perceptrons, each taking in one or more input numbers from a prior layer and outputting a single number to one or more perceptrons in the next layer.
The computer scientist building the neural network determines its design—how many perceptrons the system uses, where the input data comes from, how the perceptrons connect, what step function gets used, and how the system interprets the output numbers. However, the learner itself decides what weights are given to each input as the numbers move through the network, and what biases are applied to each perceptron. As the weights and biases change, the outputs will change. The learner’s goal is to keep adjusting the weights and biases used by the system until the system produces answers using the input information that most closely approximates the actual, known answers.
Returning to the handwriting recognition example, remember that we broke down each letter image into 400 pixels, each with a greyscale value. Each of those 400 data points would become a input number into our system and be fed into one or more of the perceptrons in the first input layer. We add some hidden layers in the middle. Finally, we would have an output layer of 26 perceptrons, one for each letter. The output perceptron with the highest output value will tell us what letter the system thinks the image represents.
Then, we pick some initial values for the weights and biases, run all the samples in our training set through the system, and see what happens. Do the output answers match the real answers? Probably not even close the first time through. So, the system begins adjusting weights and biases, with small, incremental changes, testing against the training set and continuously looking for improvements in the results until it becomes as accurate as it is going to get. Then, the test set is fed into the system to see if the determined set of ideal weights and biases produces accurate results. If it does, we now have an algorithm that we can use to interpret handwriting.
It might seem a little like magic, but even a relatively simple neural network, properly constructed, can be used to read handwriting with a high degree of accuracy. Neural networks are particularly good at sorting things into categories, especially when using a discrete set of input data points. What letter is it? Is it a picture of a face or something else? Is a proof of claim possibly objectionable or not?
Other machine learning algorithms play an important role in interpreting unstructured data and tasks like natural-language processing. They can identify relationships among words or concepts. The computer does not understand the words, what the concepts are, or what they mean, but it can identify the relationships as relationships and, like a parrot that repeats what it hears, convey the impression of understanding.
Machine Learning in Action
My examples are basic, designed to provide some understanding of what are fairly abstract systems. Machine learners come in many flavors—some suitable for performing basic sorting mechanisms, and others capable of identifying and indexing complex relationships among information in unstructured databases. Some systems work using fairly simple programs and can run on a typical office computer, and others are highly complex and require supercomputers or large server farms to accomplish their tasks.
To understand the power of machine learning systems compared with nonlearning analytic tools, let’s revisit the first example in the article: ROSS Intelligence. ROSS is built on the IBM Watson system, although it also includes its own machine learning systems to perform many of its tasks. Watson’s search tools employ a number of machine learning algorithms working together to categorize semantic relationships in unstructured textual databases. In other words, if you give Watson a large database of textual material dealing with a particular subject, Watson begins by indexing the material, noting the vocabulary and which words tend to associate with other words. Even though Watson does not actually understand the text’s meaning, it develops, through this analysis, the ability to mimic understanding by finding the patterns in the text.
For example, when you conduct a Boolean search in a traditional service for “definition /s ‘adequate protection,’” the service searches its database for an exact match for those terms applying the Boolean search logic provided. ROSS does something different. It looks within the search query for word groups it recognizes and then finds the results it has learned to associate with those word groups. You should not even have to use the term “adequate protection” to get an answer back discussing the concept when that is the appropriate answer to your question. So long as your question triggers the right associations, the system will, over time, learn to return the correct responses.
The key is that a machine learning system learns. In a way, we do the same thing ROSS does. The first time we research a topic, we might look at a lot of cases and go down a lot of dead ends. The next time, we are more efficient. After dealing with a concept several times, we no longer need to do the research. We remember what the key case is, and at most we check to see if there is anything new. We know how the cases link together, so the new materials are easy to find.
A machine-learning-based research tool can do this on a much broader scale. It learns not just from our particular research efforts, but from those of everyone who uses the system. As the system receives more use, it continues to use user feedback to assess how its model performs and allow for periodic retraining. As a result, it will become extremely adept at providing immediate responses to the most common user queries. Even though the system does not have an understanding of the material in the same manner as a human, its ability to track relationship building over a large scope of content and a large number of interactions allow it to behave as you might, if you had researched a particular point or issue thoroughly many times previously. This provides a research tool far more powerful than existing methodologies.
Legal tools based on machine learning have enormous application. Learners already in use by lawyers help with legal research, categorize document sets for discovery purposes, evaluate pleadings and transactional documents for structural errors or ambiguity, perform large-scale document review in M&A, or identify contracts affected by systemic change—like the Brexit. General Motors’ legal department, and likely other large companies, are exploring using machine learning techniques to evaluate and predict litigation outcomes and even help choose which law firms they employ. Machine learning is not the solution for every question, but it can help answer a large number of questions that simply were not answerable in the past, and that is why the advent of machine learning in the legal profession will prove truly transformational.
Interested in learning more about AI and data? Join the Section’s new Legal Analytics Working Group
The Legal Analytics Working Group’s mission is to explore, and educate business lawyers about, the use of math and economics in the substantive practice of business law. Specifically, we are focused on the use and application of:
- Data analytics, statistics and probability theory
- Economic theories of choice under uncertainty
- Game theory
- Behavioral economics
- Machine learning, and
- Computational law aka “QuantumLaw”
The legal community has already started adopting these complex mathematical and economic techniques. This trend is accelerating.


